Training Mika-X's Brain: First Tests
Category: AI, Human-Robot Interaction, Machine Learning, Neural Networks, Deep Learning

Today, let's look at the technical details of the first training the emotion recognition models and the results I've got.
Model Architecture: Designing Mika-X's Emotional Brain
For facial emotion recognition, I designed a Convolutional Neural Network (CNN) with multiple layers to extract increasingly complex features from facial images:
- Input (48x48 grayscale image)
- Convolutional Layer (32 filters) → Batch Normalization → ReLU Activation (common pattern used in CNN designed to extract features from input data)
- Convolutional Layer (32 filters) → Batch Normalization → ReLU Activation
- Max Pooling → Dropout (25%)
- [Additional convolutional blocks...]
- Flatten → Dense Layers → Output (7 emotion classes)
For voice emotion recognition, I used a different approach since audio data has different characteristics:
- Audio Features (MFCCs, chroma, spectral features)
- Dense Layer (256 units) → Batch Normalization → ReLU Activation → Dropout
- Dense Layer (128 units) → Batch Normalization → ReLU Activation → Dropout
- Dense Layer (64 units) → Batch Normalization → ReLU Activation → Dropout
- Output (8 emotion classes)
Training Process: Teaching Mika-X to Understand Emotions
Training a neural network is like teaching a child through repeated examples. Here's how my training process worked:
1. Forward Propagation: The model makes predictions based on input data
2. Loss Calculation: I measure how wrong these predictions are
3. Backpropagation: The model adjusts its internal parameters to reduce errors
4. Optimization: I use the Adam optimizer (no pun intended, that's the actual optimizer name) to efficiently update parameters
I trained the models for up to 50 epochs (complete passes through the training data), with early stopping to prevent overfitting. I also used techniques like batch normalization and dropout to improve generalization.
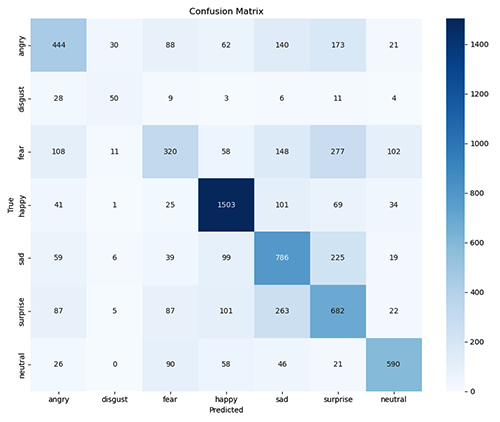
Performance Metrics: How Well Does Mika-X Understand Emotions?
After training, I evaluated our models using several metrics:
Facial Emotion Recognition:
- Accuracy: 60.95%
- Best Performance: Happy (82% F1-score)
- Most Challenging: Fear (38% F1-score)
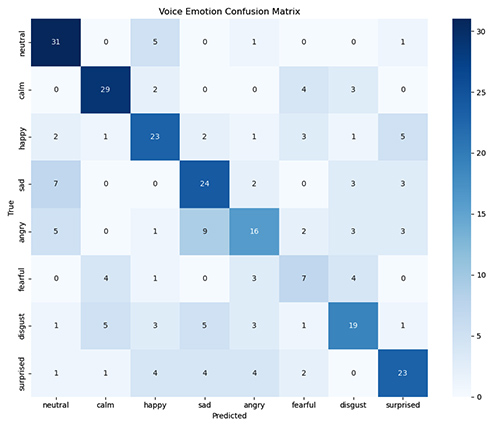
Voice Emotion Recognition:
- Accuracy: 59.72%
- Best Performance: Calm (74% F1-score)
- Most Challenging: Fearful (37% F1-score)
These results might seem modest at first glance, but they're actually pretty decent for initial emotion recognition, which is challenging even for humans. Emotions are subjective, context-dependent, and often expressed subtly (which is the most challenging for a machine to get right). For these tests, my emotions were greatly exagerrated.
Understanding the Confusion Matrices
The confusion matrices reveal interesting patterns in how the models classify emotions:
- Happy is consistently well-recognized across both modalities, probably becasue smiling is the easiest facial expression to recognize.
- Fear and Surprise are often confused with each other (understandably, as they share similar facial expressions, often distinguished by subtle changes).
- Neutral expressions sometimes get classified as other emotions, suggesting our models might be overly sensitive.
Integration: Combining Facial and Voice Analysis
The main goal here, is to combine both modalities. My fusion approach weights the confidence scores from both models, with higher confidence given to more certain predictions. This multi-modal approach helps compensate for weaknesses in individual models. For example, if the facial model detects "sadness" with 70% confidence and the voice model detects "neutral" with 55% confidence, my system would likely conclude the user is feeling sad.
Real-Time Implementation: Bringing Mika-X to Life
At this point, I've implemented a real-time system that:
- Captures video from your webcam
- Records audio when prompted (for voice analysis and records)
- Processes both streams simultaneously
- Displays detected emotions and confidence scores
- Generates appropriate responses from Mika-X
The system runs currently at approximately 10-15 FPS on my ancient workstation, which is sufficient (fortunately) for interactive use.
Challenges and Solutions
During this stage, I encountered several interesting challenges:
1. Lighting Variations: Different lighting conditions significantly affect facial recognition. I implemented histogram equalization to mitigate this.
2. Background Noise: Voice recognition struggled with noisy environments, so I added noise reduction filters to improve audio quality.
3. Real-time Performance: Processing both video and audio simultaneously is computationally intensive for my good ol' NVidia Quadro P4000. I optimized the models the best I could and used threading to maintain responsiveness.
4. Emotion Ambiguity: Real emotions are often mixed or subtle. The confidence thresholds help handle ambiguous cases gracefully, although with the current model, it's as far as I can go.
What's Next for Mika-X?
Next steps will include:
1. Personalization: Training the models on my individual expressions and voices, cruical to get higher accuracy
2. Context Awareness: Incorporating situational context to improve emotion recognition
3. Temporal Analysis: Tracking emotion changes over time for more nuanced understanding
4. Response Refinement: Developing more sophisticated and natural response generation
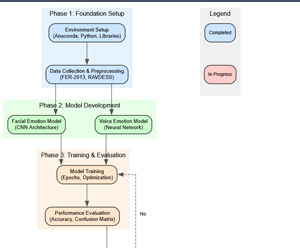
You can check the rough plan for the foreseeable future on the graph below. Till next update, where I'll start with personalization. Cheers!
- Adam