Training Mika-X's Brain: ...aaaand back to the drafting table.
Category: AI, Human-Robot Interaction, Machine Learning, Neural Networks, Deep Learning

So, I was ready to test my chat app for real this time! Proud of myself, I launched it and...
Facial recognition worked... somewhat. Mika seemed to react, although my default expression was mostly categorized as “happy” (with greenscreen behind me, like during one of the photo sessions) or as “angry” if I didn’t include it. When I really showed an angry face, apparently I was showing disgust. Hmm...
On the positive side, Mika’s avatar updated very smoothly, and the green rectangle stuck to my face much better than before fine-tuning, following me pretty accurately about 90% of the time.
Voice recognition turned out to be a complete disaster, though. Not only did Mika ignore any emotion I tried to convey, she also constantly labeled everything I said as “angry” with 100% conviction, looking at me all frightened. I mean, I was maybe a bit disappointed, considering the overall performance of the app, but it quickly turned out both models looked great only on paper.
Fixing stuff and re-training models
There was no choice — I rolled up my sleeves and got to work.
First, I took care of the voice. After a few extra tests, all I could get was “neutral” voice, instead of “angry” 100% of the time. That could indicate imbalanced training data (too many “neutral” samples, which would be strange, considering I prepared 100 each), insufficient training on other emotions, or overfitting to neutral patterns. Other issues like feature extraction, learning rate, or even the model architecture not being complex enough to capture emotional patterns could also be at play.
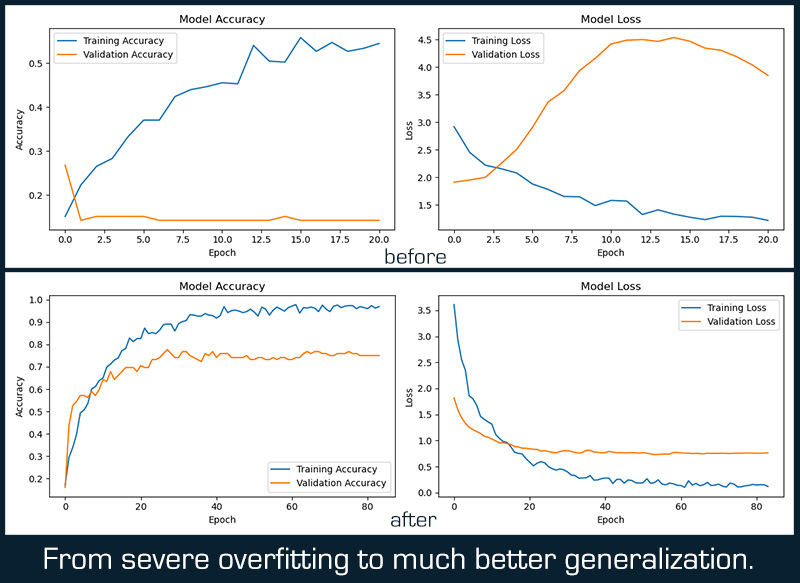
I started training another model, but I kept hitting a strange roadblock: cross-validation results (75–80%) showed the model could learn effectively, but the test performance was really poor (around 14–15%), indicating a significant difference between training and test data distributions. No matter what tweaks I tried, I couldn’t get past it. 😞
ISSUE
After some tinkering, and a bunch of diagnostic and debugging scripts later, I finally knew what was up. A couple of things had been happening behind the scenes that finally came to light:
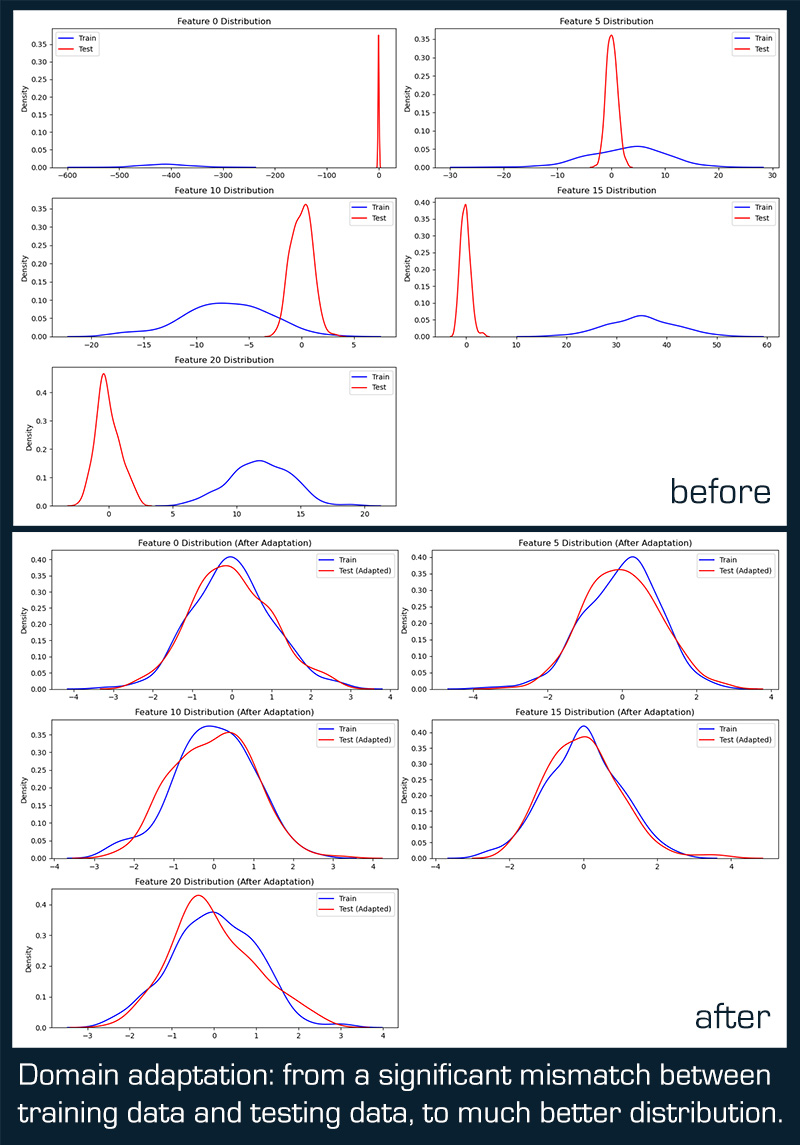
1) Labeling issue: somehow, emotions ended up being labeled differently in config.py and in the training script, leading to complete model confusion.
2) Missing data: apart from labeling, the data used for learning and the data used for testing weren’t even. Because of incorrect data splitting, the training set was missing two emotions: fear and surprise — it had zero samples of them (while the test set had samples for all emotions).
Because of these, two things were happening:
Data distribution mismatch: due to wrong labeling and data differences, the training and test data had completely different distributions. Training data had much larger values (std ~45) compared to test data (std ~1). This suggested the training data wasn’t normalized while the test data was.
Model bias: due to all these problems, the model was heavily biased towards predicting just one emotion, like “angry” or “neutral” (80%+ recall), while ignoring most other emotions.
FIXING VOICE RECOGNITION (again)
So, first, I corrected the labels and got rid of any that were redundant or not used anymore. Then, by running a more detailed script, I performed data splitting one more time, making sure both sets — training and testing — received all the data they should have. Finally, I had:
1. All 7 emotions represented in both training and test sets
2. Balanced distribution (80 samples per emotion in training, 20 in test)
3. Proper stratified split maintaining the same proportions
However, the training was still tricky, and the new model had trouble learning. Just in case, I analyzed voice features across all 7 emotions, but the results were fine, with discriminability ratio: 0.95. They did show low individual feature correlations, which meant a combination of features was necessary to distinguish emotions. PCA explained variance ratio showed that I needed more components to capture the emotional patterns.
The results meant that the main issue was either the model architecture or the training process. After taking these into consideration, I was able to break into 0.26 accuracy. Still very low, but the model finally started predicting various emotions, not just one. Bias towards “angry” and “neutral” was still strong (42.1% each), and some emotions were still getting 0% precision/recall (disgust, fear, surprise).
To overcome this, I used the ensemble approach again and trained three models at once. I also:
- enhanced class weighting (higher weights to poorly performing emotions: disgust, fear, surprise)
- used a smaller batch size of 16 for better gradient estimation
- simplified architecture by removing excessive regularization that might have prevented learning
- included better model selection to automatically choose the best-performing model
- added audio augmentation to increase dataset diversity
That finally did the trick, and the new model achieved a decent 79% accuracy on the 7-class emotion classification task.
It also had:
- Balanced Predictions: no single emotion dominated (11.4% to 22.1% distribution)
- High Precision/Recall: most emotions had 60–95% precision and recall
- Validation Accuracy: 77.68% (good generalization without overfitting)
Neutral: 95% precision, 95% recall, 95% F1-score
Angry: 100% precision, 80% recall, 89% F1-score
Sad: 89% precision, 85% recall, 87% F1-score
Areas for Further Improvement:
Happy: high precision (92%) but lower recall (60%) — model is being too conservative
Fear: decent but could be improved (67% precision, 70% recall)
Surprise: lower precision (58%) but high recall (90%) — model is over-predicting this class
FIXING FACIAL RECOGNITION (again)
Because of the voice recognition labeling blunder, I had a sneaky suspicion that a similar case happened with the image data, which would explain the constant labeling of my neutral expression as “happy” or “angry.”
I ran a simple diagnostic script that confirmed my suspicion. So, I fixed the labeling in the config file, preprocessed the data (again), and started training models (again). Eventually, I got model with 64% accuracy, which is definitely lower than the (seemingly) awesome 96%, but it had much better distribution across all the emotions:
- Fear: 44% recall
- Sad: 48% recall
- Angry: 60% recall
- Disgust: 70% recall
- Happy: 83% recall
- Neutral: 64% recall
- Surprise: 76% recall
The final adjustments included:
- Targeted oversampling for difficult emotions (fear, sad, angry)
- Boosted class weights to further emphasize these emotions during training
- Optimized learning rate schedule with a minimum floor to prevent the learning rate from becoming too small
- Balanced dropout and regularization to prevent overfitting while allowing the model to learn effectively
Both models, facial and voice, still required more work, but for now, they were good enough for trials. Obviously, once I got everything to work well, I got creative again, and added a whole bunch of features I didn't originally planned. 😆 What features exactly?
You'll see in the next post - live testing of Mika-X v01. Cheers.
- Adam